Определение частотности элементов при помощи Python
Одна из распространённых задач для программистов — определение частотности каких-либо элементов. В настоящей заметке мы посмотрим, как можно решить эту задачу средствами Python 3.
Определим для себя, что мы будем анализировать частнотность букв английского алфавита (без учёта знаков препинания и пробелов) в каком-либо англоязычном тексте. Следовательно, наше техническое задание будет включать некоторую подготовительную работу (очистка текста и подготовка его к анализу), собственно подсчет частотности и заключительную часть (вывод информации в удобочитаемом для пользователя виде).
Таким образом, наша программа может состоять из нескольких частей, выполняющих следующую работу:
- Получение текста от пользователя.
- Очистка текста (вынесем её в отдельную функцию).
- Анализ частотности различными способами.
- Вывод информации о частоте встречаемости тех или иных букв английского алфавита (также можно реализовать в виде отдельной функции).
Логика программы анализа частотности
Весь алгоритм программы можно поместить в функцию
main():

Для начала нам вполне достаточно такого кода основной функции.
Понятно, чем является переменная text: это неизменяемый
объект класса str. А вот как будет выглядеть
переменная letters? Логичнее всего представить её в
виде списка букв английского алфавита, причём в том порядке и
количестве, в каком эти буквы будут расположены в оригинальном
тексте. Таким образом, строка 'Hello, World 2021!'
станет у нас списком
['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd'].
Легко заметить, что буква l попадается в списке 3 раза,
буква o — 2 раза, а остальные буквы
(h, e, w, r и
d) — только по одному разу каждая. Такую вот
статистику и будет собирать наша программа.
А вы заметили, что в списке приведены только строчные английские буквы? Нам не важен регистр букв в исходном тексте; поэтому заглавные (прописные) буквы на этапе очистки текста будут преобразованы в строчные.
Очистка текста и преобразование его в список букв
Итак, текст приходит к нам в необработанном виде и подвергается очистке от знаков препинания. На этапе очистки мы также преобразуем все заглавные буквы в строчные, т.е. приведём весь текст к нижнему регистру.
Можно, конечно, создать список всех возможных знаков препинания, но
проще всего воспользоваться готовым решением — константой
punctuation, которые содержатся в стандартном модуле
string:

и получаем !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~.
Кстати, в тексте могут попадаться и цифры — их мы тоже не
будем считать. Для удаления знаков пунктуации и цифр воспользуемся
регулярными выражениями, предоставляемыми модулем re из
стандартной библиотеки.
Теперь можно написать последовательность команд для очистки текста. Мы приводим текст к нижнему регистру, удаляем знаки пунктуации и цифры, затем разбиваем текст на слова (простейший способ убрать пробелы), соединяем слова и делаем из очищенного текста список букв:
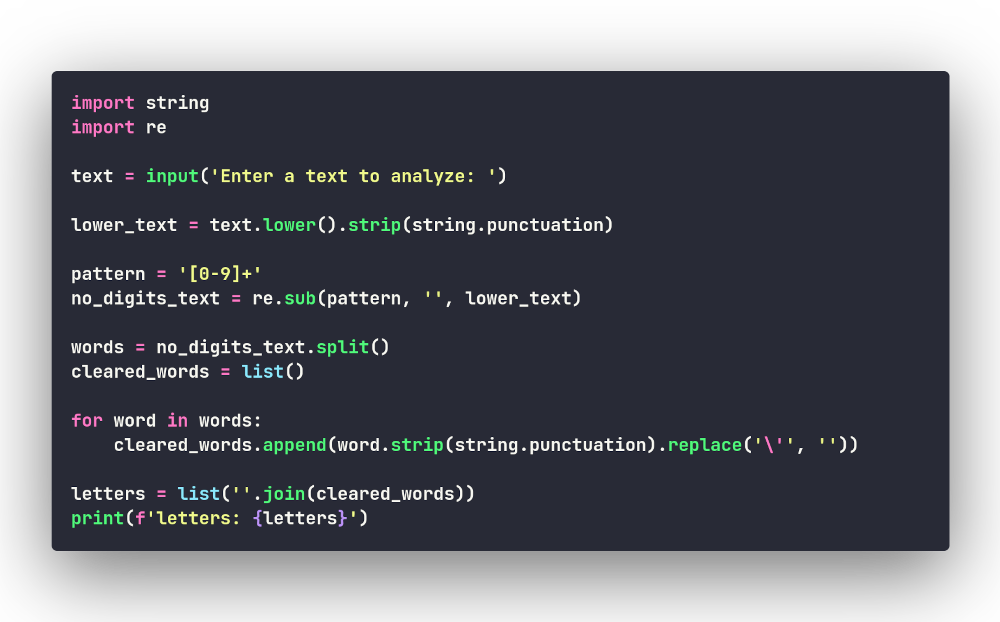
Запустив данный код с тестовой строкой и добавив команды вывода после каждой операции очистки, мы увидим следующее:
text: Hello, World 2021!
hello, world
['hello,', 'world']
letters: ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
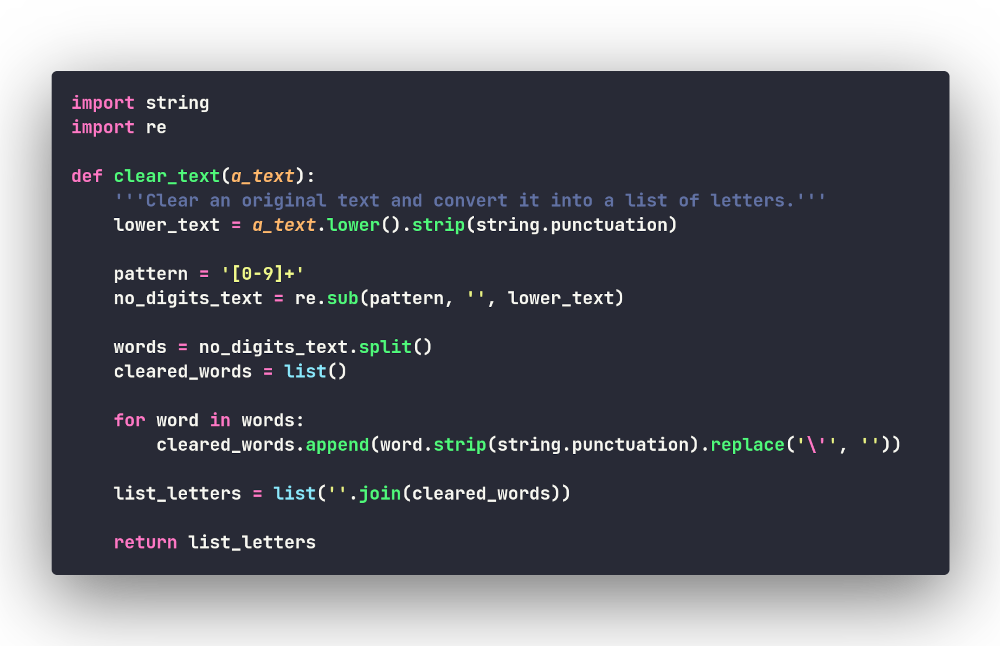
Всё работает! Давайте поместим код в функцию
clear_text():
Вывод итоговой статистики
Прежде чем перейти собственно к коду, анализирующему статистику использования букв в тексте, давайте подумаем, а в каком виде мы должны получить эту информацию? И здесь сразу напрашивается такая структура данных, как словарь. Буквы станут у нас уникальными ключами, а счётчики их использований — значениями словаря, например для фразы 'Hello, World 2021!' словарь будет выглядеть так:
{'h': 1, 'e': 1, 'l': 3, 'o': 2, 'w': 1, 'r': 1, 'd': 1}
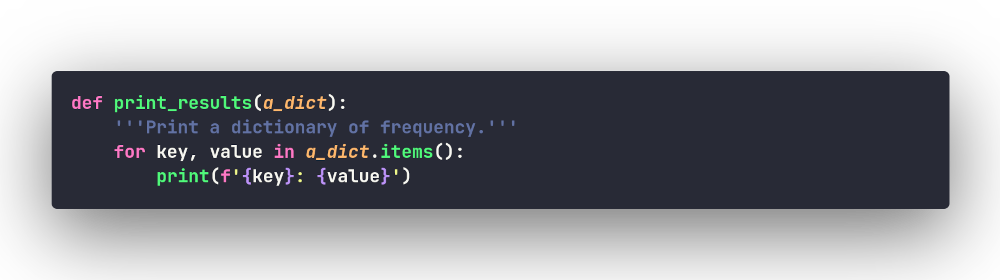
Отлично, а теперь давайте напишем код, который будет печатать
словарь в удобном для восприятия виде. Для этого воспользуемся
методом .items(), который возвращает ключи и связанные
с ними значения, примерно так (сразу оформим код в функцию):
Анализ частотности методом грубой силы
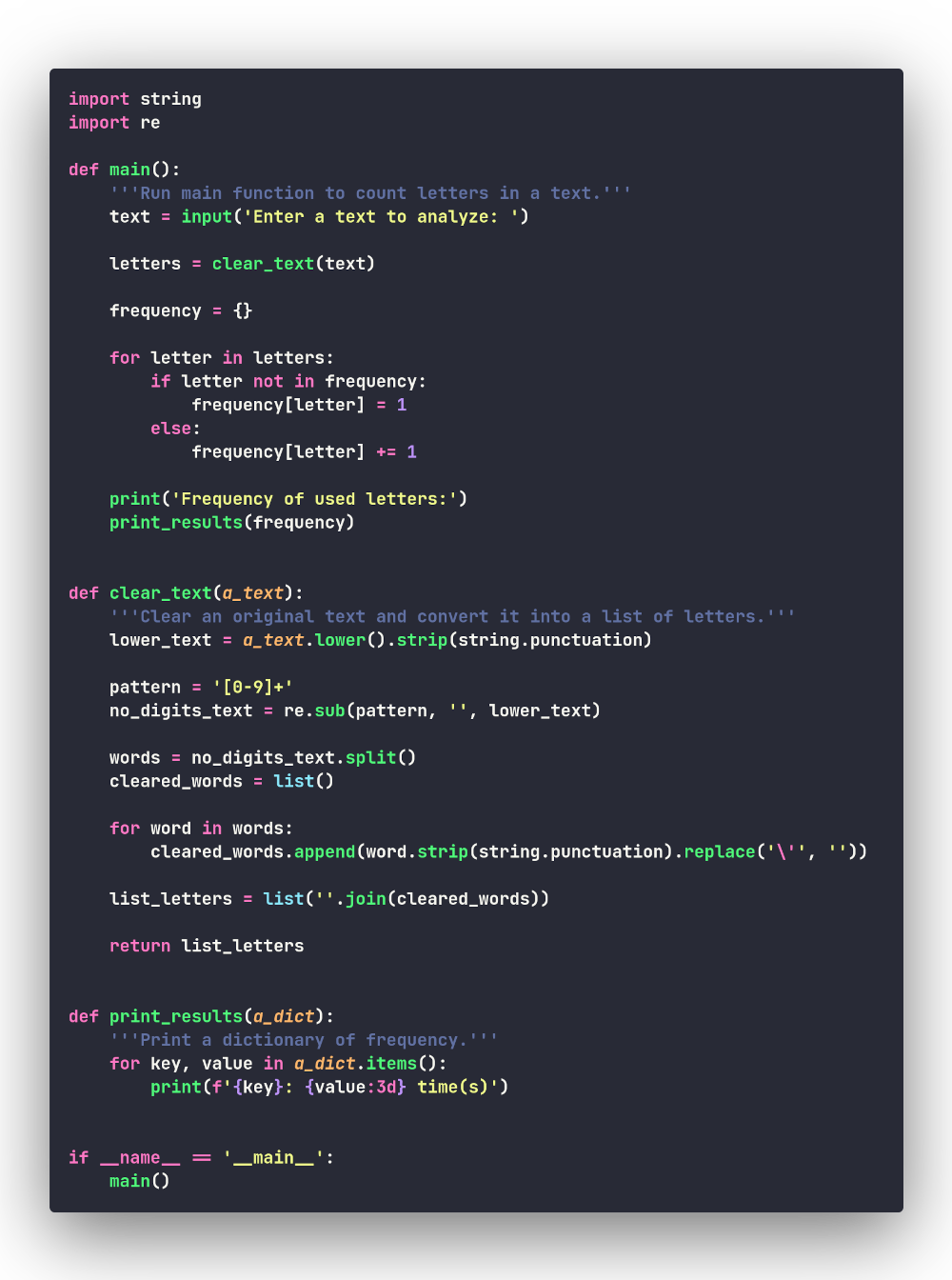
Вот теперь пришло время заняться ядром нашей программы — кодом, который и будет вести статистику использования букв в англоязычном тексте. Данную задачу можно решить многими способами, но для начала попробуем применить метод грубой силы, т.е. самый простой (примитивный) способ. Начнём перебирать словарь букв, каждую букву будем добавлять в новый словарь в виде ключа (если её там нет, присвоим её счётчику значение 1; если есть — увеличим уже имеющееся значение на 1):
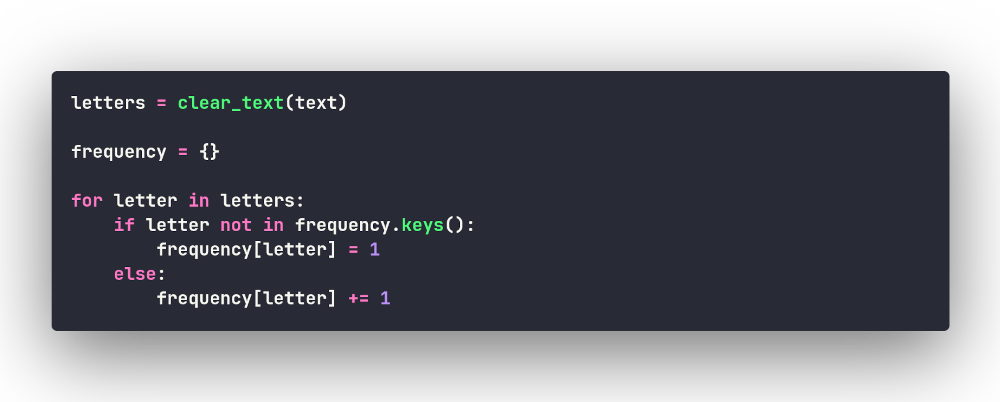
Если мы запустим список букв фразы 'Hello, World 2021!' и включим тестовый вывод, то увидим, как фомируется наш словарь:
{'h': 1}
{'h': 1, 'e': 1}
{'h': 1, 'e': 1, 'l': 1}
{'h': 1, 'e': 1, 'l': 2}
{'h': 1, 'e': 1, 'l': 2, 'o': 1}
{'h': 1, 'e': 1, 'l': 2, 'o': 1, 'w': 1}
{'h': 1, 'e': 1, 'l': 2, 'o': 2, 'w': 1}
{'h': 1, 'e': 1, 'l': 2, 'o': 2, 'w': 1, 'r': 1}
{'h': 1, 'e': 1, 'l': 3, 'o': 2, 'w': 1, 'r': 1}
{'h': 1, 'e': 1, 'l': 3, 'o': 2, 'w': 1, 'r': 1, 'd': 1}
Всё работает, соберём программу и проведём некоторый её рефакторинг для лучшего отображения данных:
Enter a text to analyze: Hello, World 2021!
Frequency of used letters:
h: 1 time(s)
e: 1 time(s)
l: 3 time(s)
o: 2 time(s)
w: 1 time(s)
r: 1 time(s)
d: 1 time(s)
Файл с кодом данной версии программы: bruteforce.py.
Питонический способ подсчёта частотности
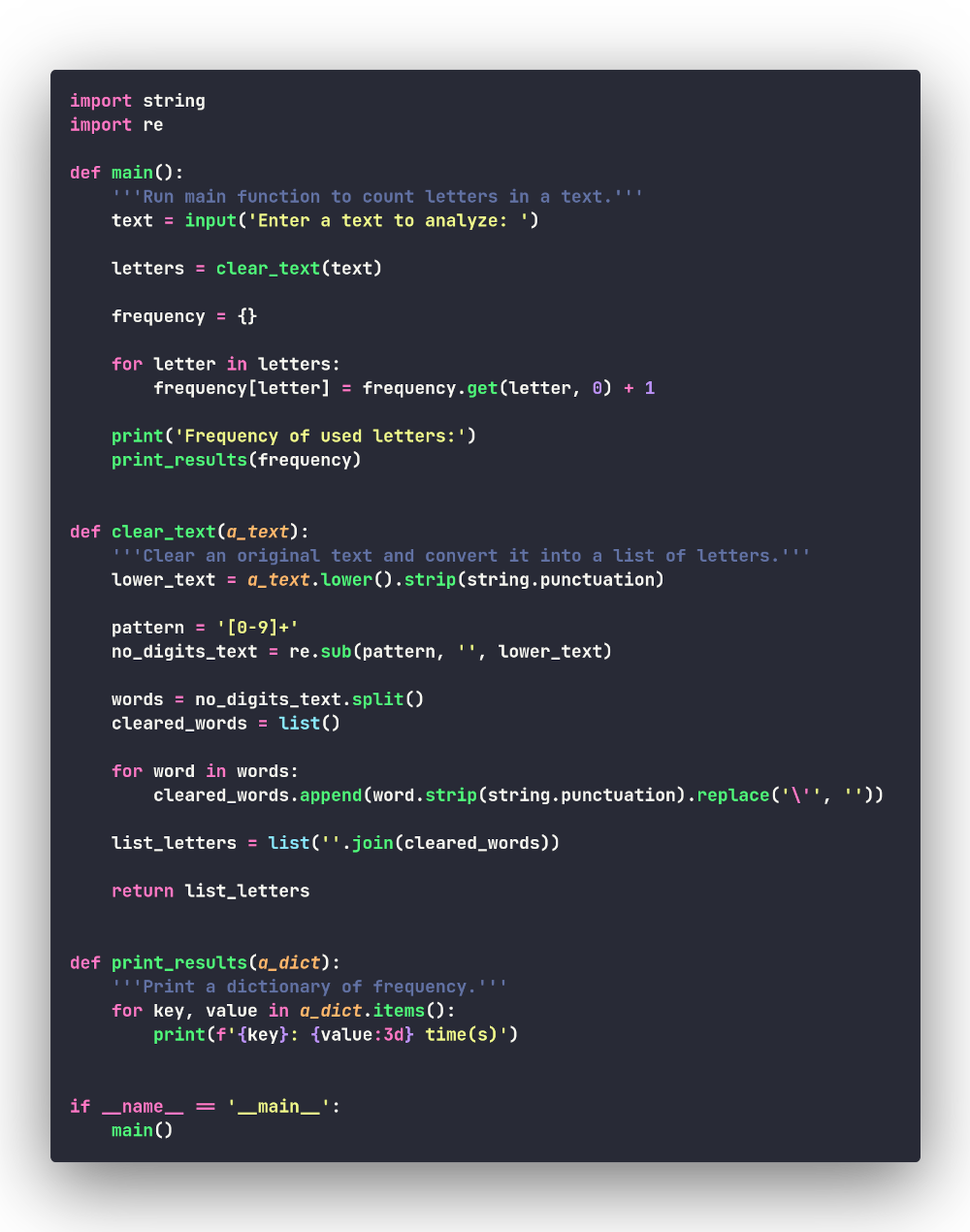
Мы решили задачу методом грубой силы, но существуют более изящные (питонические) варианты, и вот — самый известный из них:

Как работает этот код: если ключа нет в словаре (т.е. буква ещё не
добавлена в новый словарь), метод .get() возвращает
значение, опредённое пользователем (как будто у нас уже было
значение 0) и увеличивает его на единицу; если же ключ
есть — просто увеличивает существующее значение.
Полный текст программы с данным вариантом кода:
Выход программы идентичен:
Enter a text to analyze: Hello, World 2021!
Frequency of used letters:
h: 1 time(s)
e: 1 time(s)
l: 3 time(s)
o: 2 time(s)
w: 1 time(s)
r: 1 time(s)
d: 1 time(s)
Файл с кодом данной версии программы: pythonic.py.
В принципе, на этом варианте можно было бы остановиться, вспомнив принцип из "Дзен Python", что должен существовать один (и желательно только один) способ решить какую-либо задачу. Но, раз мы не голландцы, в отличие от создателя языка Гвидо ван Россума, то далее рассмотрим ещё несколько не менее эффектных вариантов.
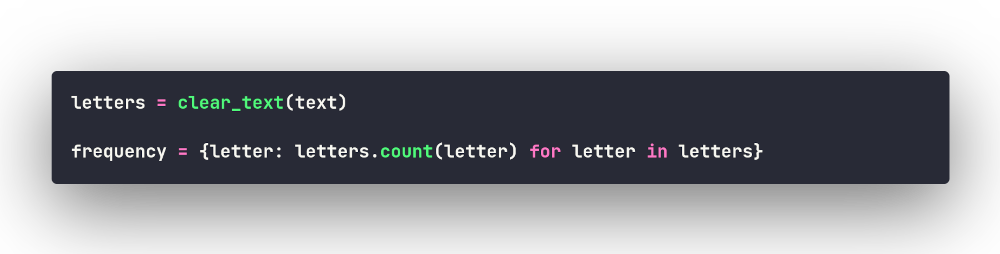
Используем метод .count()
Метод .count() проводит поиск значения по списку и
возвращает количество вхождений значения в список. Воспользовавшись
воззможностями генерирования словарей, получим нужный нам словарь
"на лету":
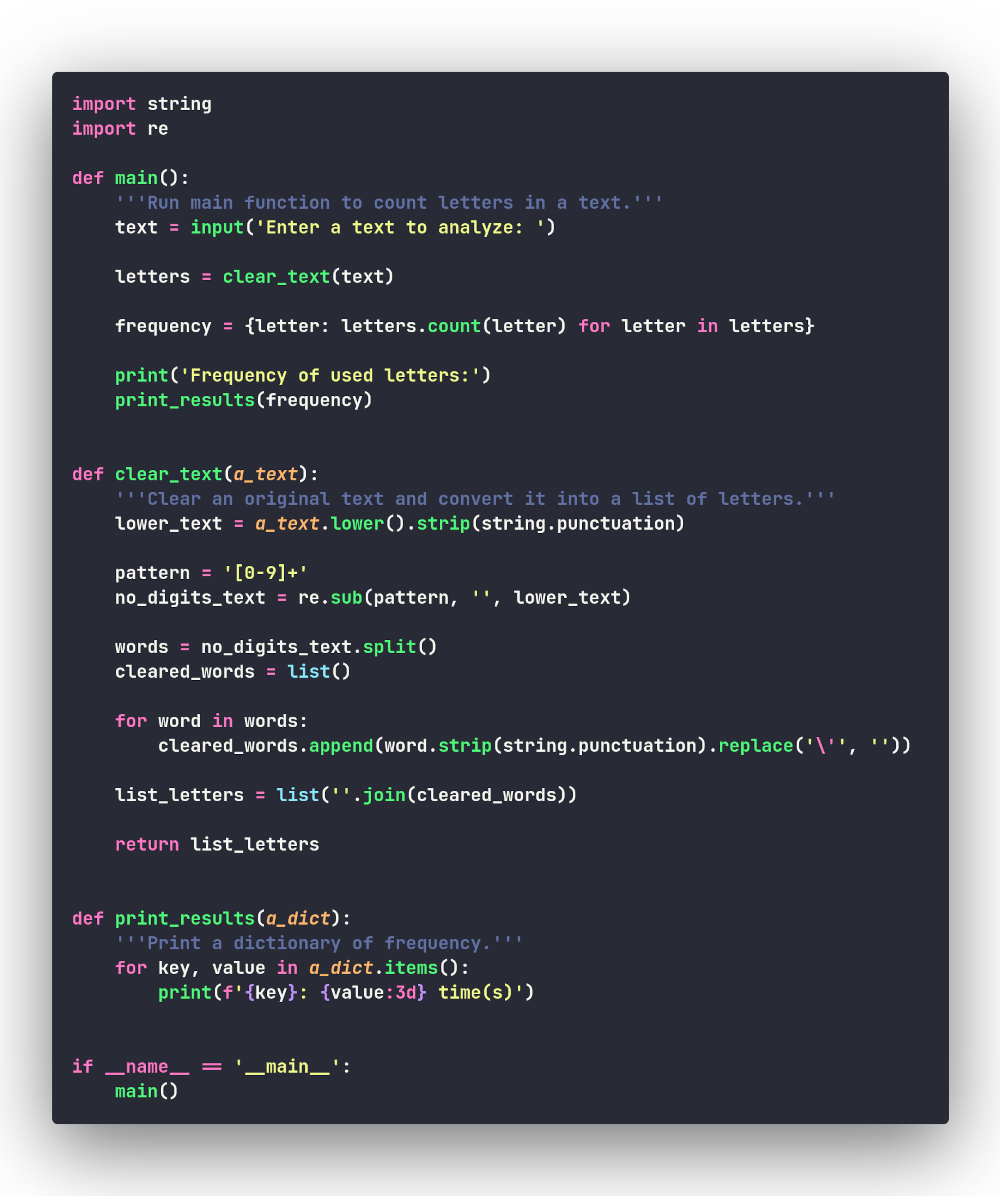
Очень изящно, не так ли? Соберём новый вариант программы:
Выход программы также идентичен:
Enter a text to analyze: Hello, World 2021!
Frequency of used letters:
h: 1 time(s)
e: 1 time(s)
l: 3 time(s)
o: 2 time(s)
w: 1 time(s)
r: 1 time(s)
d: 1 time(s)
Файл с кодом данной версии программы: count.py.
Определяем частотность при помощи defaultdict
Есть обычные словари, а есть defaultdict из модуля
collections. Обычный словарь, если обратиться к
несуществующему ключу, инициирует исключение KeyError;
напротив, defaultdict создаст недостающий элемент.
Элементы нового словаря по умолчанию создаются с помощью
int(), возвращающего целочисленный объект
0:
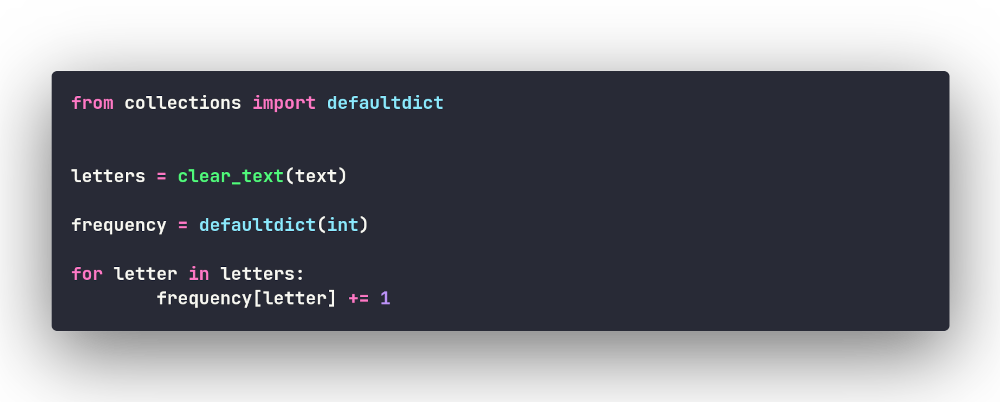
Похоже на приведённый выше питонический способ, но с использованием встроенных батареек! И теперь наша программа выглядит так:
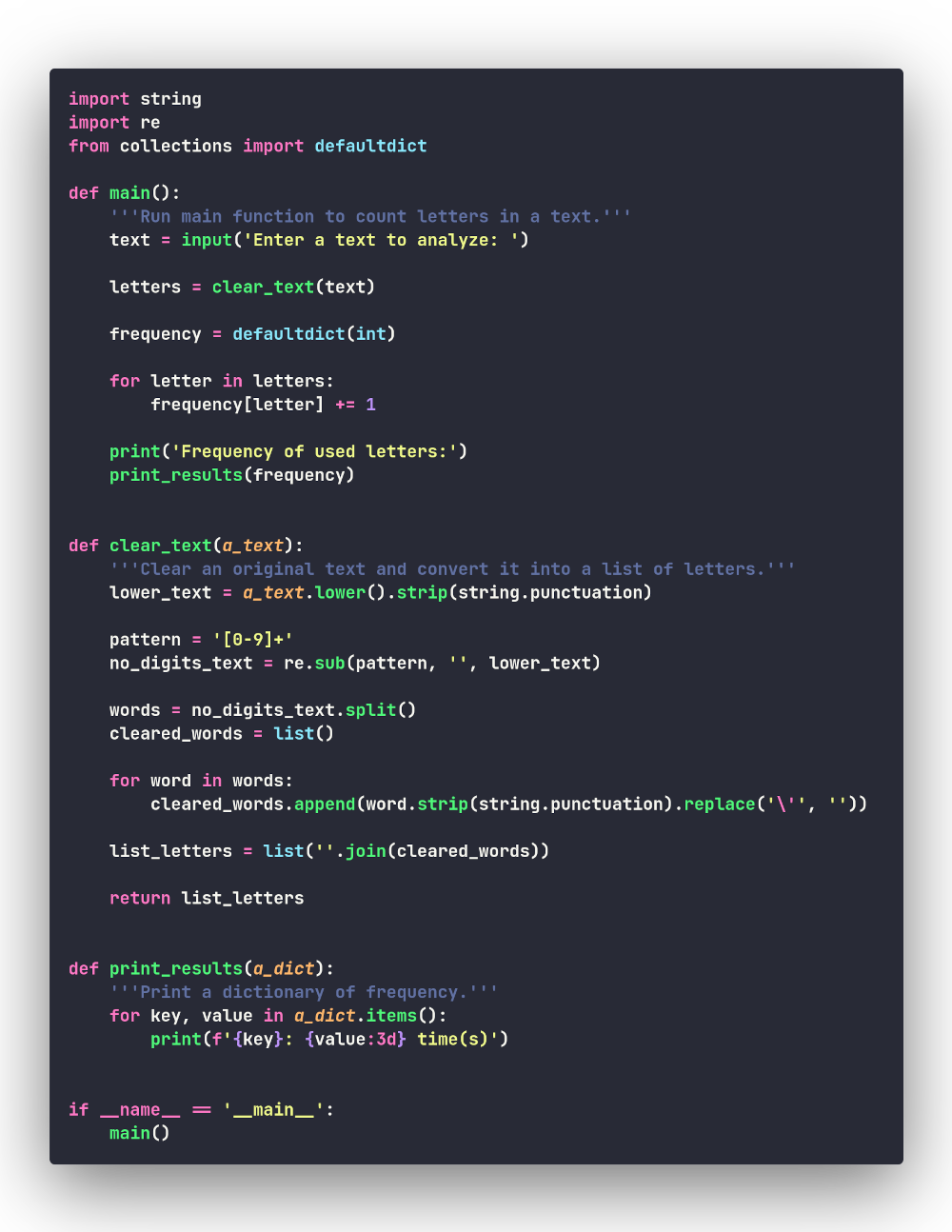
Всё тот же вывод программы:
Enter a text to analyze: Hello, World 2021!
Frequency of used letters:
h: 1 time(s)
e: 1 time(s)
l: 3 time(s)
o: 2 time(s)
w: 1 time(s)
r: 1 time(s)
d: 1 time(s)
Файл с кодом данной версии программы: defaultdict.py.
Counter — универсальный счётчик
Наконец, последний из рассмотренных нами способов использует другие
батарейки (на этот раз не обычные, а алкалиновые) —
Counter из того же модуля collections. Это
самое простое в использовании решение, поскольку
Counter сделает за вас всю работу:
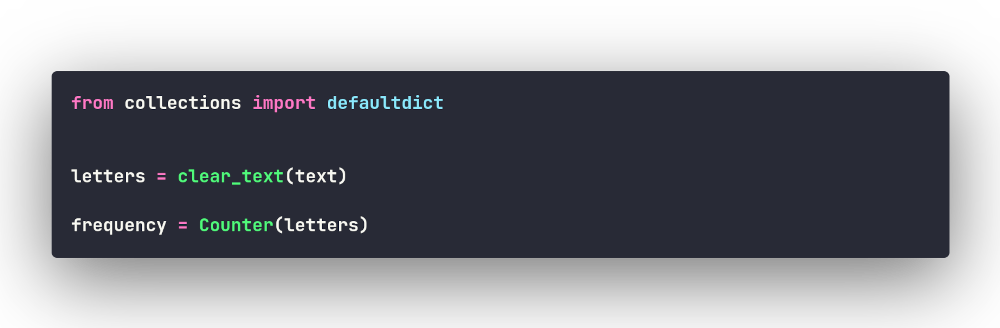
Теперь наша программа стала такой:
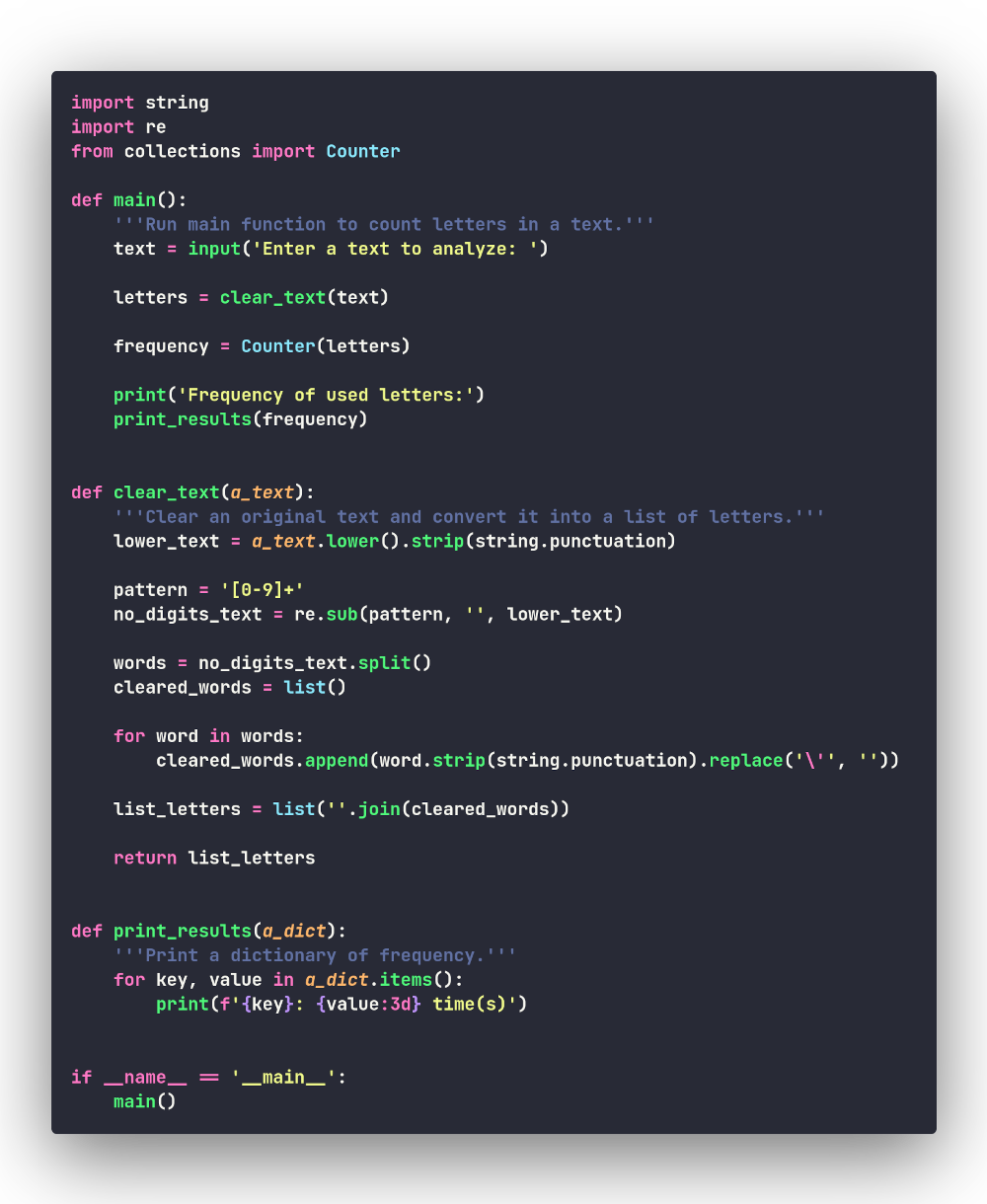
Вывод программы:
Enter a text to analyze: Hello, World 2021!
Frequency of used letters:
h: 1 time(s)
e: 1 time(s)
l: 3 time(s)
o: 2 time(s)
w: 1 time(s)
r: 1 time(s)
d: 1 time(s)
Файл с кодом данной версии программы: counter.py.
Но Сounter вообще многое умеет делать. Например, он
работает со строками (и мы могли бы не разбивать строку на отдельные
буквы, а скормить её данному счётчику целиком); проводить
арифметические операции с элементами; складывать, вычитать,
объединять различные счётчики; показывать наиболее встречаемые
элементы с помощью метода .most_common([n]), где
n — количество топовых элементов. Например, если мы
ходим вывести две самых встречаемых буквы:
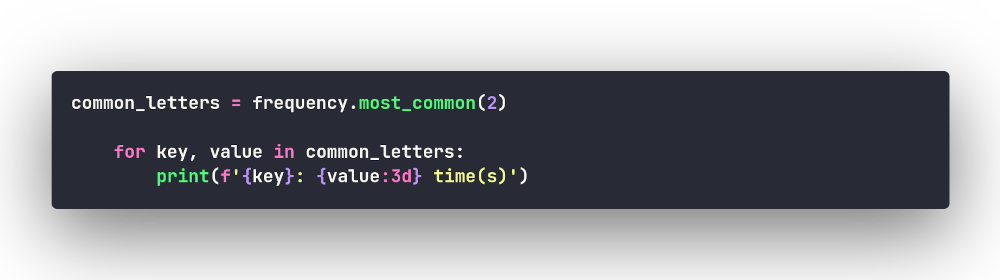
Добавим такой вывод в нашу программу:
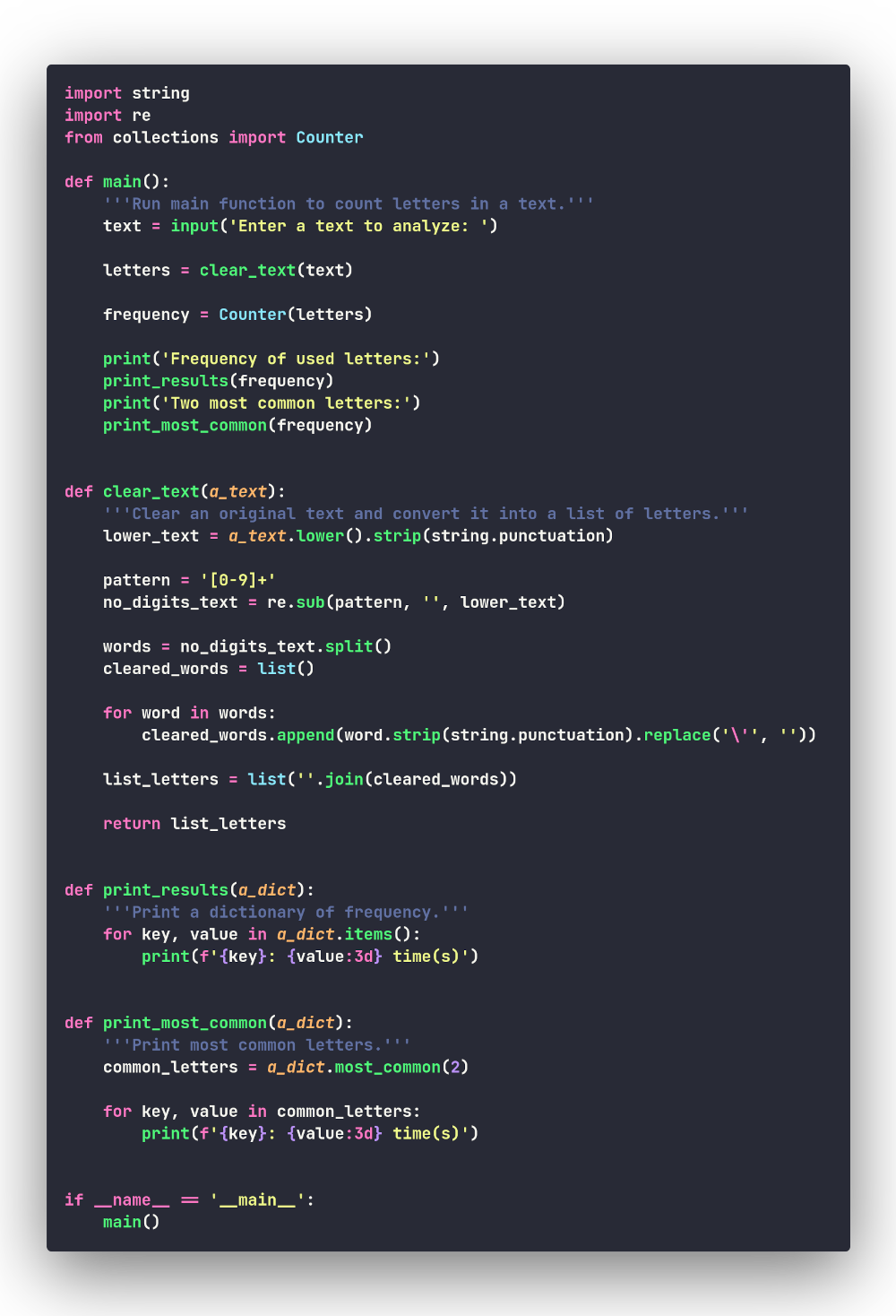
Вывод программы следующий:
Enter a text to analyze: Hello, World 2021!
Frequency of used letters:
h: 1 time(s)
e: 1 time(s)
l: 3 time(s)
o: 2 time(s)
w: 1 time(s)
r: 1 time(s)
d: 1 time(s)
Two most common letters:
l: 3 time(s)
o: 2 time(s)
Файл с кодом усовершенствованной версии программы: counter_mostcommon.py.
Вот и всё, что я хотел рассказать вам о способах подсчёта частотности.